> ## Documentation Index
> Fetch the complete documentation index at: https://docs.retellai.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Exceptions to Our Per-Minute Pricing
> Billing adjustments that may affect Retell call costs: 10-second minimum for dynamic opening messages and extra charges for long prompt token counts.
## Overview
While we generally bill based on actual call duration, certain call characteristics may result in adjusted billing to ensure fair pricing for our services.
## Rule 1: Minimum Duration for Dynamic Opening Messages
**When it applies:** Calls shorter than 10 seconds that use dynamic opening messages when AI speaks first
**Billing adjustment:** Minimum charge of 10 seconds
 **Example:**
* Call duration: 6 seconds
* Dynamic opening messages: Enabled
* Billed duration: 10 seconds (4 seconds additional charge)
**Why:** Dynamic opening messages require processing time regardless of call length, so we ensure a minimum charge to cover these costs.
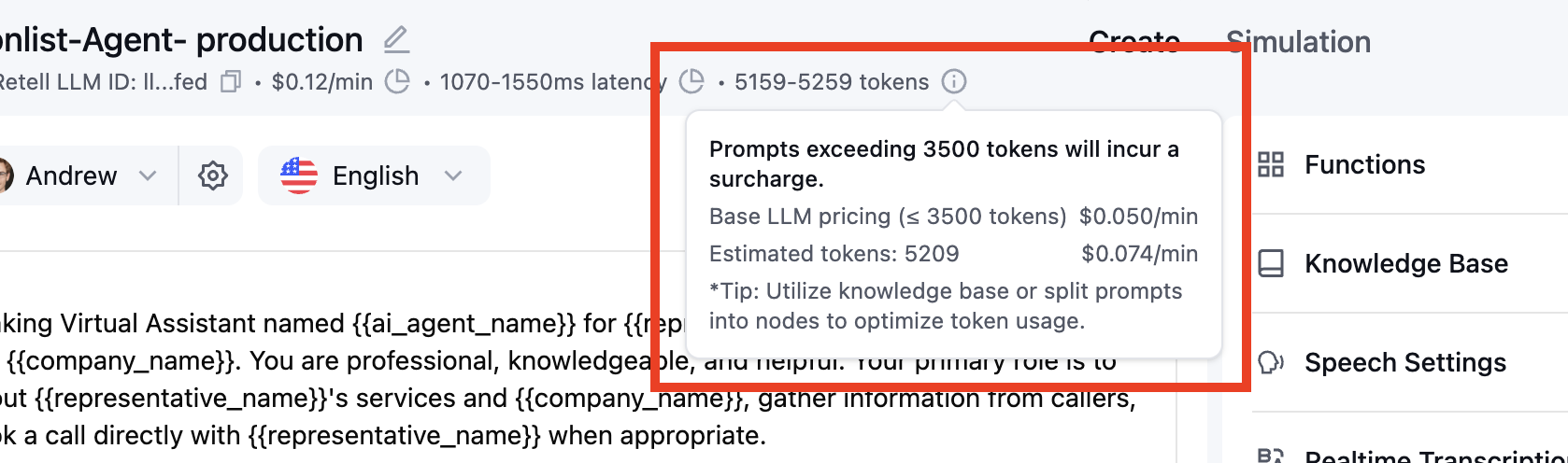
## Rule 2: LLM Price Scaling for > 4,000 Token Prompt Length
**When it applies:** Agents that use more than 4,000 LLM tokens in their prompts
**Billing adjustment:** Duration is scaled proportionally based on token usage
**What's included in token calculation:**
* global prompt
* functions (tool descriptions)
* state / node prompt
* transcript between agent and user
* tool call history and results
[Flex mode](/build/conversation-flow/flex-mode) is a common trigger for this rule.
It compiles all node prompts, transitions, and tool descriptions into a single LLM
context, which can push the token count well above 4,000.
**Price calculation:**
* Scaling Factor = Prompt LLM Tokens ÷ 4,000
* Billed Duration = Original Duration × Scaling Factor (rounded up)
**Example:**
* Call duration: 60 seconds
* LLM tokens used: 4,800
* Scaling factor: 4,800 ÷ 4,000 = 1.2
* Billed duration: 72 seconds (12 seconds additional charge)
**Example:**
* Call duration: 6 seconds
* Dynamic opening messages: Enabled
* Billed duration: 10 seconds (4 seconds additional charge)
**Why:** Dynamic opening messages require processing time regardless of call length, so we ensure a minimum charge to cover these costs.
## Rule 2: LLM Price Scaling for > 4,000 Token Prompt Length
**When it applies:** Agents that use more than 4,000 LLM tokens in their prompts
**Billing adjustment:** Duration is scaled proportionally based on token usage
**What's included in token calculation:**
* global prompt
* functions (tool descriptions)
* state / node prompt
* transcript between agent and user
* tool call history and results
[Flex mode](/build/conversation-flow/flex-mode) is a common trigger for this rule.
It compiles all node prompts, transitions, and tool descriptions into a single LLM
context, which can push the token count well above 4,000.
**Price calculation:**
* Scaling Factor = Prompt LLM Tokens ÷ 4,000
* Billed Duration = Original Duration × Scaling Factor (rounded up)
**Example:**
* Call duration: 60 seconds
* LLM tokens used: 4,800
* Scaling factor: 4,800 ÷ 4,000 = 1.2
* Billed duration: 72 seconds (12 seconds additional charge)
 **Why:** Larger LLM prompt lengths incur greater costs due to token-based pricing from our underlying model providers, so we scale the billing accordingly to reflect these increased expenses.
**Why:** Larger LLM prompt lengths incur greater costs due to token-based pricing from our underlying model providers, so we scale the billing accordingly to reflect these increased expenses.