> ## Documentation Index
> Fetch the complete documentation index at: https://docs.retellai.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Step 1: Configure global settings
> Configure global settings for a Retell conversation flow agent — voice, language, LLM, denoising, and other agent-level options on the empty canvas.
## Agent Global Settings
Click on empty canvas and click setting to access global setting. Here's where you set a lot of agent level settings.
1. Open the voice selection dropdown menu:
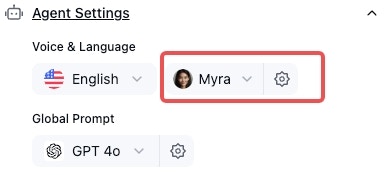 2. Listen to the available voice samples and select the voice you want to use for the agent:
2. Listen to the available voice samples and select the voice you want to use for the agent:
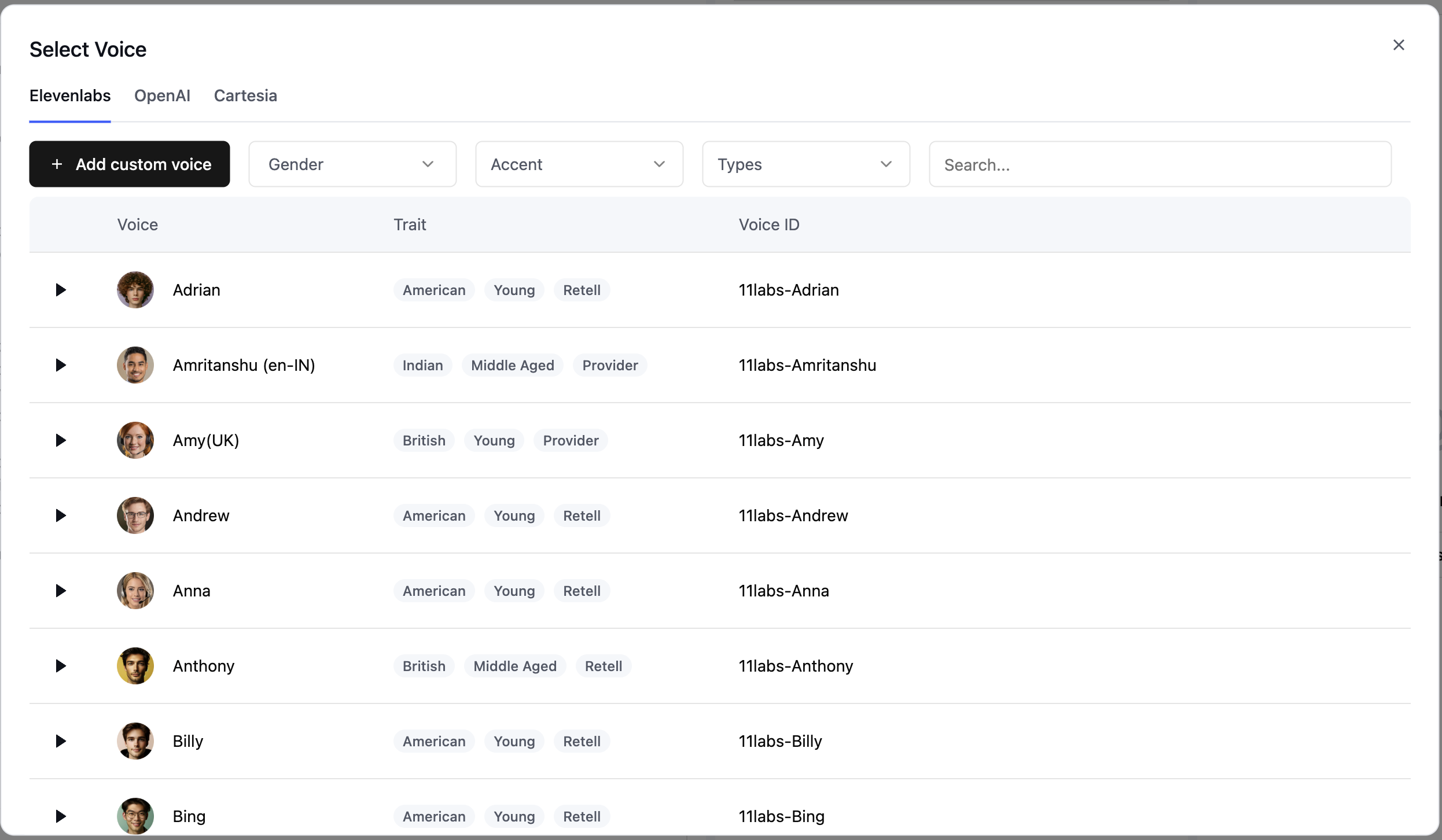 **Custom Voices**: You can also add voices from the ElevenLabs community or clone voices by clicking "Add custom voice". Learn more in our [voice configuration guide](/build/voice).
3. You can also adjust a couple of voice settings:
* voice temperature to make the voice more variant or stable.
* voice speed to make the agent speak faster or slower.
* voice volume to make the agent speak louder or quieter.
* voice model (if applicable): when using certain voice providers, you can choose between different models. Check out the dashboard for detailed nuances of each model.
Pick the language(s) the agent will understand and speak. This affects speech recognition, voice pronunciation, and the language the agent responds in — you do not need to add a "respond in X" instruction to your prompt.
To support multiple languages, switch the selector to **Multiselect** and pick the specific languages you want; for best accuracy, prefer a single language when possible. See [Set language for your agent](/agent/language) and [Configure a multilingual agent](/agent/multilingual) for details.
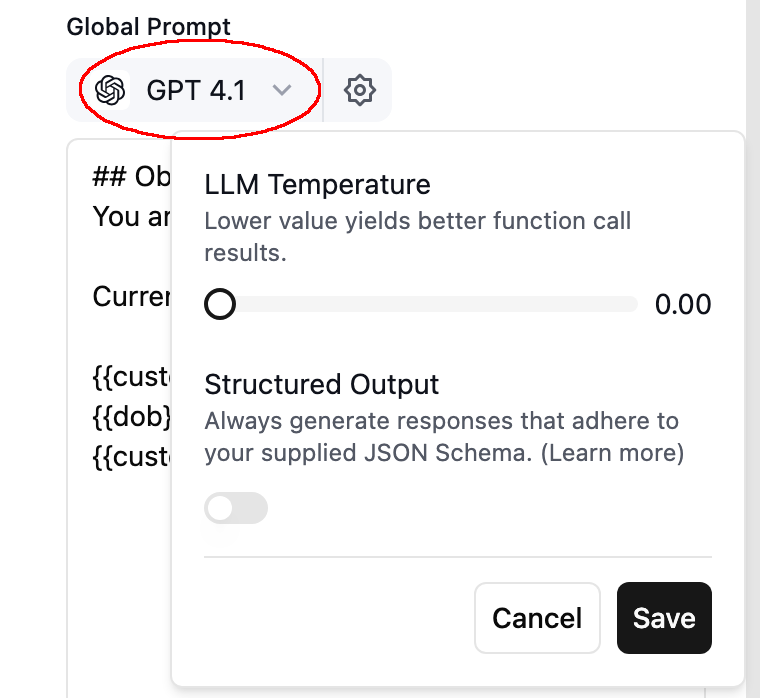
Select the model you want to use for the agent. Please note that you can override this within individual nodes. Optionally you can tune the LLM temperature to make answers more variant or more stable.
We recommend starting with GPT-4.1, which offers an optimal balance of:
* Response quality
* Latency
* Cost-effectiveness
**Custom Voices**: You can also add voices from the ElevenLabs community or clone voices by clicking "Add custom voice". Learn more in our [voice configuration guide](/build/voice).
3. You can also adjust a couple of voice settings:
* voice temperature to make the voice more variant or stable.
* voice speed to make the agent speak faster or slower.
* voice volume to make the agent speak louder or quieter.
* voice model (if applicable): when using certain voice providers, you can choose between different models. Check out the dashboard for detailed nuances of each model.
Pick the language(s) the agent will understand and speak. This affects speech recognition, voice pronunciation, and the language the agent responds in — you do not need to add a "respond in X" instruction to your prompt.
To support multiple languages, switch the selector to **Multiselect** and pick the specific languages you want; for best accuracy, prefer a single language when possible. See [Set language for your agent](/agent/language) and [Configure a multilingual agent](/agent/multilingual) for details.
Select the model you want to use for the agent. Please note that you can override this within individual nodes. Optionally you can tune the LLM temperature to make answers more variant or more stable.
We recommend starting with GPT-4.1, which offers an optimal balance of:
* Response quality
* Latency
* Cost-effectiveness
 Here's where you specify the agent's persona, identity, guardrails, etc. This set of text will be available in every node, and will influence all response generation.
Here's where you can supply contexts to agent via documents, urls, texts. Read more at [Knowledge Base Guide](/build/knowledge-base).
Here's a lot of options that allow you to finetune how your agent interacts with user.
* Background sound: select a background sound that plays throughout the whole call to mimic an environment like call center, making the conversation more humanlike and engaging.
* Responsiveness: how responsive the agent is. Set it lower if you want agent to respond slower, which can be useful when talking to folks like elderly. Reducing responsiveness by 0.1 adds 0.5 seconds of agent wait time.
* Interruption Sensitivity: how fast the agent gets interrupted by user interruptions. Set it lower if you want agent to be more resilient to background speech or user interruptions.
* Backchanneling: Set up how often and what words the agent uses to acknowledge users.
* Boosted Keywords: Provides some biases towards certain words, making it easier to get recognized. Common ones are brand names, people's names, etc.
* Speech Normalization: convert entities like date, currency, numbers into plain words, which can help prevent issues where audio generated was not pronouncing those right.
* Reminder frequency: how often the agent will remind the user when user is inactive.
* Pronunciation: set up pronunciation guide for specific words.
Here's a couple of settings that's more call operation related.
* Voicemail related settings: set up voicemail detection and what to do when voicemail is detected. See more at [Handle Voicemail](/build/handle-voicemail).
* End call on silence: set up if user is inactive for a certain amount of time, the call will be ended.
* Call duration: set up maximum duration of the call.
* Pause before speaking: For the beginning of the call, if agent speaks first, it will wait for the configured duration before speaking, useful to handle scenarios when user is still picking up the phone.
Probably set up later, read more at [Post Call Analysis Guide](/features/post-call-analysis-overview).
Here's where you can set up whether to opt out sensitive data storage, and configure webhook settings for receiving call related events.
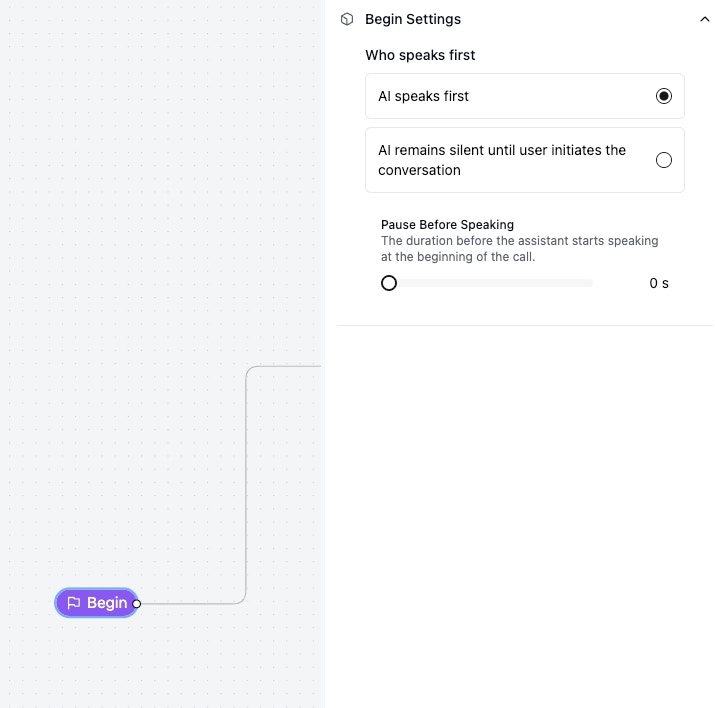
## Configure Who Speaks First
Click on `begin` icon, and you can select who speaks first in the call.
Here's where you specify the agent's persona, identity, guardrails, etc. This set of text will be available in every node, and will influence all response generation.
Here's where you can supply contexts to agent via documents, urls, texts. Read more at [Knowledge Base Guide](/build/knowledge-base).
Here's a lot of options that allow you to finetune how your agent interacts with user.
* Background sound: select a background sound that plays throughout the whole call to mimic an environment like call center, making the conversation more humanlike and engaging.
* Responsiveness: how responsive the agent is. Set it lower if you want agent to respond slower, which can be useful when talking to folks like elderly. Reducing responsiveness by 0.1 adds 0.5 seconds of agent wait time.
* Interruption Sensitivity: how fast the agent gets interrupted by user interruptions. Set it lower if you want agent to be more resilient to background speech or user interruptions.
* Backchanneling: Set up how often and what words the agent uses to acknowledge users.
* Boosted Keywords: Provides some biases towards certain words, making it easier to get recognized. Common ones are brand names, people's names, etc.
* Speech Normalization: convert entities like date, currency, numbers into plain words, which can help prevent issues where audio generated was not pronouncing those right.
* Reminder frequency: how often the agent will remind the user when user is inactive.
* Pronunciation: set up pronunciation guide for specific words.
Here's a couple of settings that's more call operation related.
* Voicemail related settings: set up voicemail detection and what to do when voicemail is detected. See more at [Handle Voicemail](/build/handle-voicemail).
* End call on silence: set up if user is inactive for a certain amount of time, the call will be ended.
* Call duration: set up maximum duration of the call.
* Pause before speaking: For the beginning of the call, if agent speaks first, it will wait for the configured duration before speaking, useful to handle scenarios when user is still picking up the phone.
Probably set up later, read more at [Post Call Analysis Guide](/features/post-call-analysis-overview).
Here's where you can set up whether to opt out sensitive data storage, and configure webhook settings for receiving call related events.
## Configure Who Speaks First
Click on `begin` icon, and you can select who speaks first in the call.