For incoming requests, only allowlist these Retell IP addresses:
100.20.5.228Understanding WebSockets
Unlike the request-response model of HTTPS, WebSockets maintain an open connection between the client and server. This facilitates two-way message exchange without needing to reestablish connections, enabling faster data streaming. For more details on WebSockets, check out this blog and WebSocket API Doc.Understand Communication Protocol
We have defined this protocol that our server would communicate with your server in. We recommend reading this first before following the guide. Generally, the protocol requires:- Your server to send the first message: send empty response to let user speak first.
- We will send live transcripts to your server, and expect responses when we need to.
- You will stream what you want your agent to say to our server, and we will speak it out.
Step 1: Add a basic websocket endpoint to your server
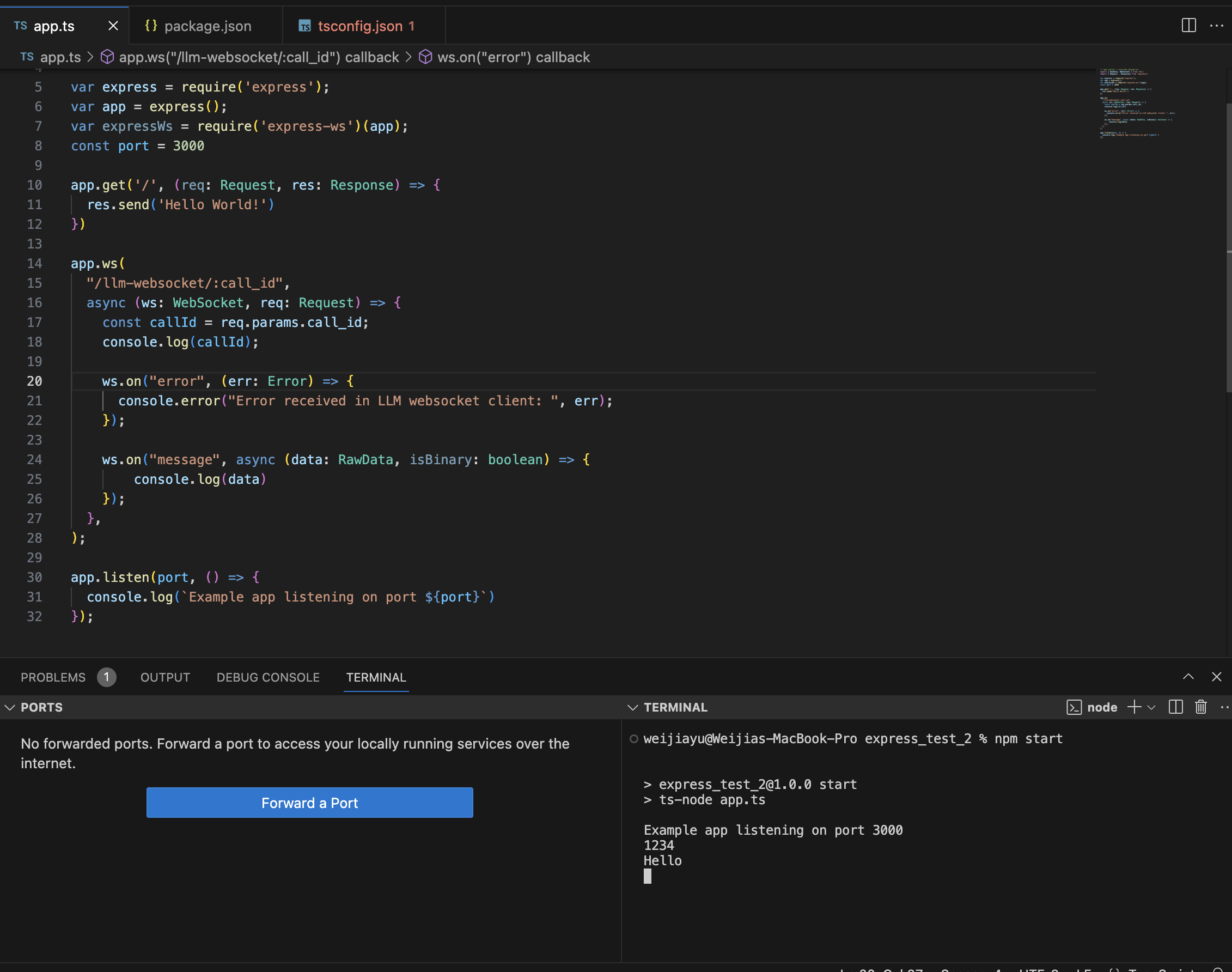
In this step, you will add a basic websocket endpoint to your express server to receive messages. If you already have a server up and running, you can add the following code next to your other routes.
Step 2: Create a Dummy Response System
In this step, you will not connect with your LLM yet. Instead, let’s just build a dummy response system that can greet with “How may I help you?”, and reply every user’s questions with “I am sorry, can you say that again?”. Don’t worry about the dumb agent, we will connect your LLM and make it smart later.llmClient.DraftResponse() to get response.
Step 3: Test your basic agent on Dashboard
At this point, you are ready to make your basic agent speak in the dashboard.-
If you deploy your server, you can get a url using your domain:
wss://your_domain_name/llm-websocket/ -
If you want to test your code locally, you can use
ngrok to generate a production url forwarding requests
to your local endpoints. You can watch this
video to learn how
to do that. After getting your ngrok url, you will have a url
wss://xxxxx.ngrok-free.app/llm-websocket/