

-
Phone Call Performance
- Reliable handling of inbound and outbound calls
- Consistent connection throughout conversations
- High voice quality
-
Agent Reliability
- Consistent low latency during interactions
-
Agent Performance
- Accurate speech transcription
- Strict adherence to prompt instructions
Our Commitment to Reliability
At Retell, we guarantee >99.9% uptime. To achieve this, we’ve invested in the following areas:- Enterprise-grade infrastructure
- Fallbacks and Resilience Features
- 24/7 Monitoring and Alerting
- 24/7 Support
Detailed Overview
-
Enterprise-grade infrastructure: We conduct extensive load testing on high traffic and maintain dedicated auto-scaling and provisioning to handle varying loads. Our enterprise-grade compute, networking, and infrastructure ensure stable performance.
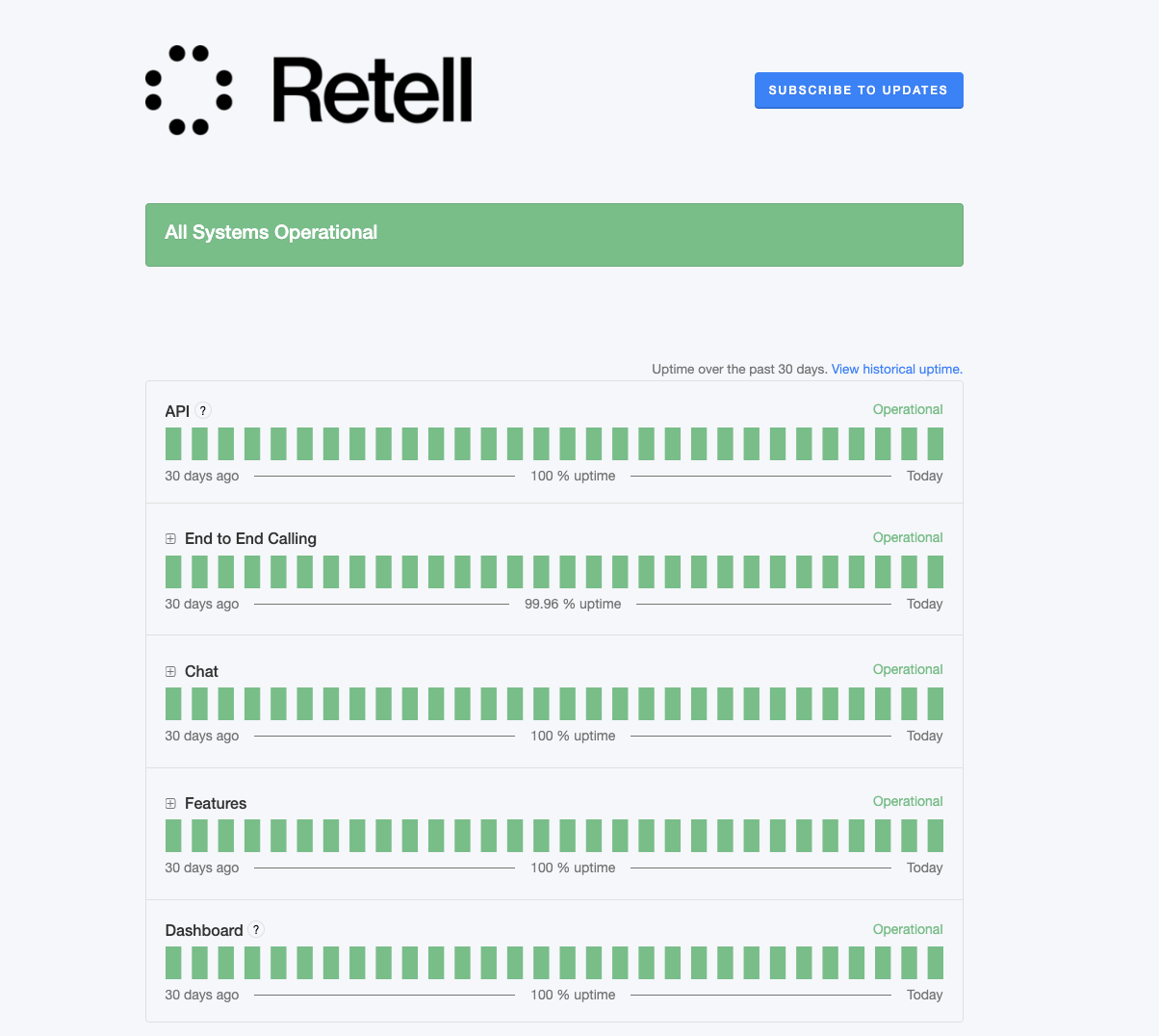
- We guarantee >99.9% uptime - Subscribe to our Status Page to get notified about any issues.
- Self-hosted models to reduce third-party dependencies.
- Stable server cluster (enterprise only): Opt in to route both calls and API requests to our stable server cluster, which receives delayed feature rollouts for added production stability. When enabled, point your API requests to
https://stable.retellai.com/instead ofhttps://api.retellai.com/. A $0.02/min surcharge applies on calls. Contact support to enable.
-
Proactive Monitoring: We maintain 24/7 latency monitoring and alerting systems to catch and address issues before they impact your operations.
- Including ASR, TTS, LLM, Knowledge base, time to first token, and network latency distribution, p75, p90, p95, p99 latencies.
- Failed calls count, ASR, LLM, TTS timeout, and error rate.
- Server CPU, GPU, memory, and network usage. Database, API response time.
-
Resilience Features: We’ve implemented fallbacks, retries, and other features to improve reliability:
- Branded Call/Verified Phone Number Features to improve call pickup rate and allowlist carrier calls
- TTS fallback and retries are automatically built in, and can be manually configured.
- LLM fallback and retries are automatically built in.
- Testing Features
-
Support System: Our dedicated support team is ready to assist if any issues arise.
- 7 days/week on-call schedule
- 24h SLA, with active support between 9 AM and 9 PM PST (lower for enterprise customers) Read more about support here.