

Overview
LLM (Large Language Model) configuration options allow you to fine-tune how your agent processes and responds to conversations. Different settings can dramatically impact your agent’s behavior, reliability, and cost.Not all options are available for every model. Check your dashboard for model-specific capabilities.
Temperature Settings
What is Temperature?
Temperature controls the randomness and creativity of your agent’s responses. It’s a value typically between 0 and 1 that affects how the model selects its next words.Temperature Guidelines
Recommendations by Use Case
- Appointment Booking: Use 0.1-0.3 for accurate data capture
- Customer Support: Use 0.3-0.5 for consistent yet natural responses
- Sales Outreach: Use 0.5-0.7 for engaging but focused conversations
- Virtual Companion: Use 0.7-0.9 for more human-like variation
Structured Output
Purpose
Structured Output ensures that LLM responses strictly follow predefined schemas, particularly important for reliable function calling. When enabled, the model is constrained to output only valid function calls with all required parameters.Benefits
- Increased Reliability: Eliminates missing or malformed function arguments
- Better Error Handling: Prevents invalid function calls from being attempted
- Consistent Data Format: Ensures all outputs match expected schemas
Trade-offs
- Slower Auto-save: Schema caching may delay agent configuration saves
- Less Flexibility: Model cannot deviate from defined structures
- Initial Setup Time: First load after changes may be slower
When to Use
✅ Enable for:- Production agents with critical function calls
- Agents handling financial or medical data
- Integration with strict API requirements
- Development and testing phases
- Agents with simple or flexible function needs
- When rapid iteration is more important than reliability
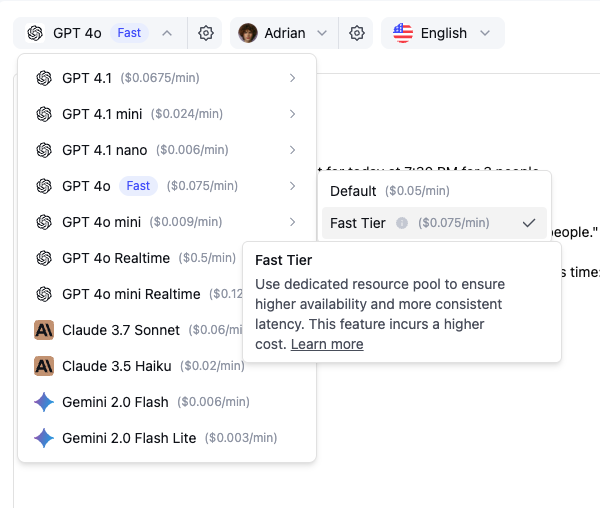
Fast Tier (Premium Performance)
What is Fast Tier?
Fast Tier routes your LLM calls through dedicated, high-priority infrastructure for superior performance and consistency. This premium option eliminates the variability you might experience with standard routing.Key Benefits
- Consistent Latency: Predictable response times for every call
- Higher Availability: Priority access to compute resources
- Reduced Variance: Minimal fluctuation in processing speeds
- Better User Experience: Smoother, more natural conversations
Cost Consideration
When to Use Fast Tier
✅ Ideal for:- High-value customer interactions
- Time-sensitive operations (emergency services, urgent support)
- Premium service tiers
- Demonstrations and sales calls
- Internal testing
- Low-volume or non-critical calls
- Cost-sensitive applications
Performance Impact
Based on our benchmarks:- 50% reduction in latency variance
- 25% improvement in average response time
- 99.9% availability vs 99.5% standard