

Call History
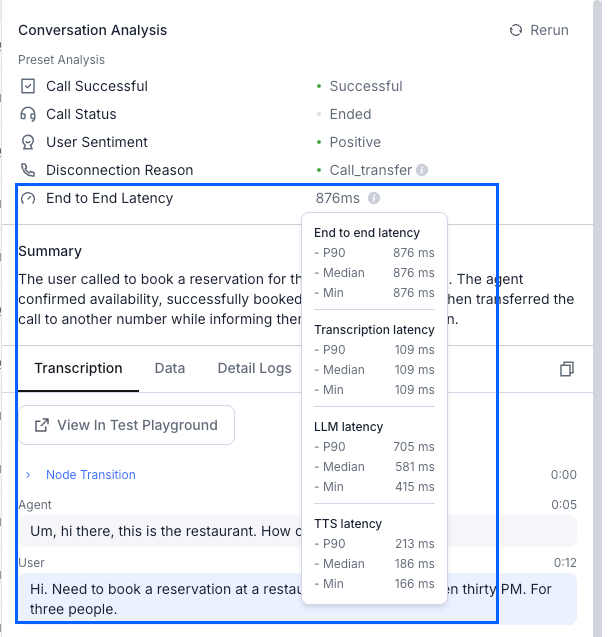
Understanding latency metrics
End-to-end latency measures the total time from when the user stops speaking until the AI agent begins responding. This includes processing time, network delays, and model inference time.Key metrics explained
- P90 (90th Percentile): 90% of calls have latency below this value.
- Median (50th Percentile): Half of the calls have latency less than this value.
- Min: The fastest response time achieved in any call.
Retrieve latency via the API
You can also retrieve detailed latency breakdowns programmatically using the Get Call API. After a call ends, the response includes alatency object with per-component metrics.
Latency breakdown fields
Thelatency object contains the following components. Not all fields are present on every call — availability depends on the call type and features used.
Each component is an object with these statistical fields:
Example response
Here is an example of thelatency portion of a Get Call response: